糊图变清晰:本地免费超分 + OCR 重绘(对比复盘)
2026-01-23 · 自用工作流 · 截图/信息图/小字优先
当“超分也不够清晰”时,把信息重建出来(而不是硬编像素)。
本次样例是一张 293×312 的低清动作网格截图:先试了传统锐化/对比增强(上限有限),再试 AI 超分(OpenCV DNN:EDSR×4/FSRCNN×4,本地 CPU 可跑,但 EDSR 内存很大),最后用 OCR 把可识别文字“重绘”回高清图层,显著提升可读性。
TL;DR
结论:对“文字+线条”的截图/信息图,单纯锐化/超分都有上限;最稳的是 OCR/矢量重绘(让文字回到可编辑的字体),AI 超分更像“把底图放大变顺”。
-
最简单(本地免费):OpenCV DNN
FSRCNN×4(快、轻;提升清晰度但不“补字”)。 -
最好看(本地免费但吃内存):OpenCV DNN
EDSR×4(质量更像“AI 修复”,但峰值 RSS ~1.45GiB)。 -
最可读(截图小字):
EDSR×4 →(可选)再放大×2 → OCR 重绘(本次样例里,这是让小字真正“回到可读”的方法)。
Best Minds
这类问题的“最懂的人”,通常来自三条线:① 超分/感知增强(SR、GAN);② 传统图像处理(锐化、去噪、反卷积、MTF);③ OCR/版式重建(把信息结构化)。
Xintao Wang(Real-ESRGAN)
- Thesis:真实世界退化(压缩、噪声、模糊)不是单一核;需要“盲超分/感知增强” 才能让细节看起来回来。
- Arguments:GAN/感知损失能补“像细节”的纹理;对人眼观感往往比插值更明显。
- Limits:对小字/符号可能会“编造笔画”;且高质量实现常依赖 GPU(本机 Vulkan/Metal 不可用时会卡住)。
Peyman Milanfar(计算摄影/增强)
- Thesis:大多数“变清晰”的上限由信息缺失决定;先稳住噪声/对比/锐化的纪律,避免过冲与假边。
- Arguments:对截图/线稿,CLAHE、去噪+轻锐化、局部对比增强能快速抬升可读性且可控。
- Limits:无法凭空恢复字体细节;越锐越容易出现光晕/振铃,视觉更“硬”但信息并未增加。
Ray Smith(Tesseract)
- Thesis:当目标是“读懂文字”,最佳策略是把文字识别出来并以矢量/字体形式重建,而不是让像素猜。
- Arguments:对低清截图,OCR 可以给出结构化文本;重绘后变成“真文字”,放大不糊、可编辑、可搜索。
- Limits:识别受限于清晰度与语言模型;对极小字需要手工校对;复杂版式重建可能需要额外规则。
Options
| 方案 | 本次表现 | 优势 | 代价/风险 | 适用 |
|---|---|---|---|---|
| 传统增强(CLAHE/锐化/反卷积) | 提升有限(上限到顶) | 快;不“编细节”;可控 | 容易更刺眼;可能出光晕/假边 | 照片/截图都能“抬一点” |
| AI 超分(OpenCV DNN · EDSR×4) | 观感明显更“像高清” | 本地 CPU 可跑;质量更像 AI 修复 | 内存高;对小字可能不准 | 想要整体更顺/更细 |
| AI 超分(OpenCV DNN · FSRCNN×4) | 比 EDSR 弱但够快 | 极快;内存低;模型小 | 细节补全能力弱 | 批量处理/机器一般 |
| AI 超分(Real-ESRGAN / waifu2x ncnn) | 本机跑不通(驱动限制) | 通常效果更强、生态成熟 | 依赖 Vulkan/Metal/CUDA | 有 GPU 或驱动齐全 |
| OCR/矢量重绘(文字层叠加) | 小字可读性最佳 | “真文字”;可编辑;放大不糊 | 需校对;只对文字有效 | 信息图/截图/表格 |
推荐默认:对“截图小字”优先走 EDSR×4 →(可选)×2 → OCR 重绘;对“真实照片”优先走
EDSR×4 或 FSRCNN×4(避免 OCR 误判带来的“假信息”)。
Workflow
-
先做传统增强对比(确认“还能挖多少信息”):
scripts/image_enhance_compare.py -
跑 AI 超分(本地 CPU):OpenCV DNN
EDSR×4/FSRCNN×4 - 若目标是“读字”:从超分结果上 OCR 抽取高置信度文字,重绘为清晰字体层(可导出 SVG)
- 把关键结果(原图/传统/AI/OCR)上传 R2,生成可分享的对比页
- 把流程固化成一个默认 skill:一键复用
Results
本次对比图已上传到 R2:image-upscale/scapula-control/20260123-175739(点击图片可全屏放大)。
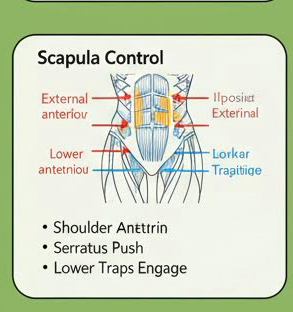
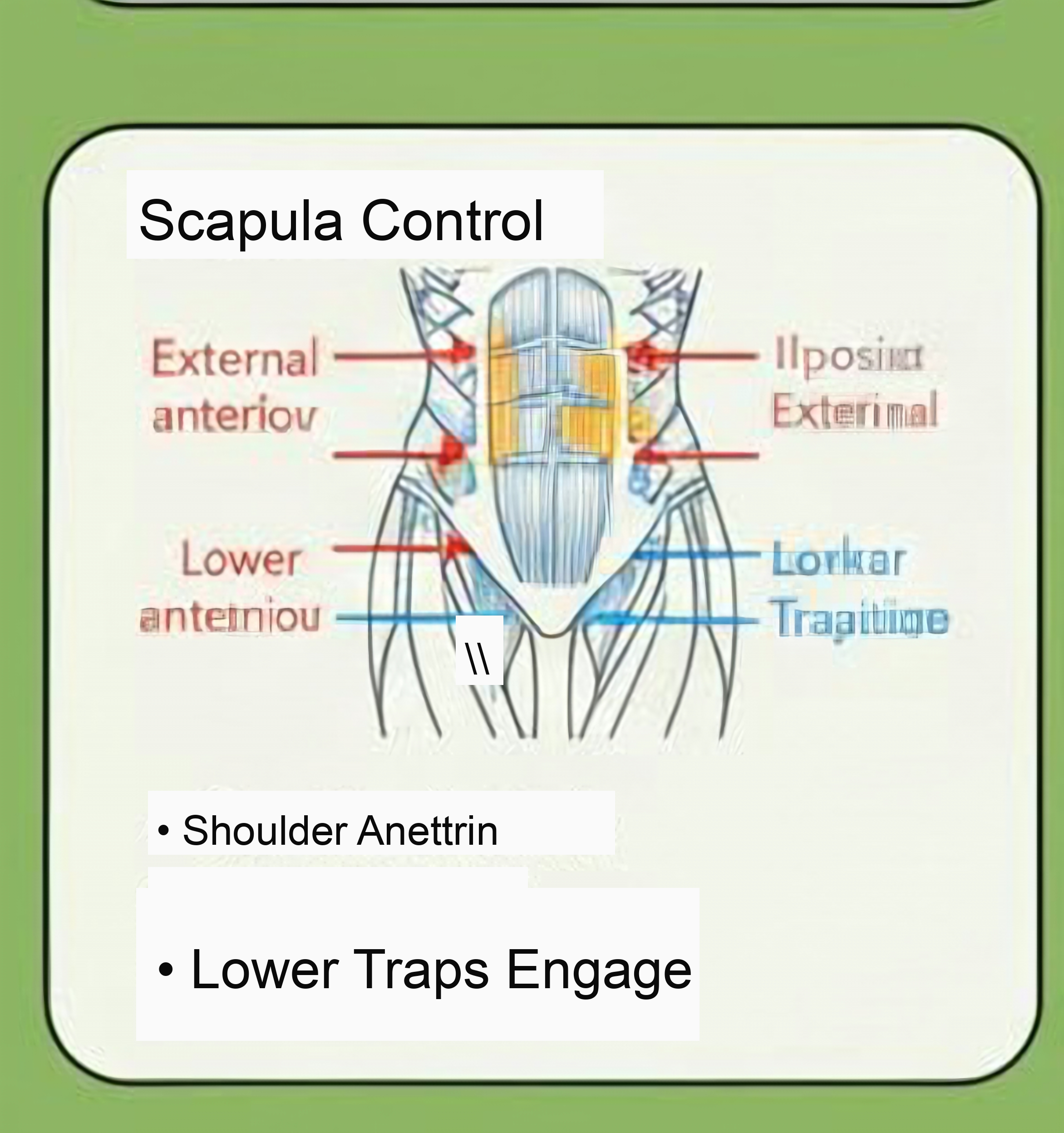
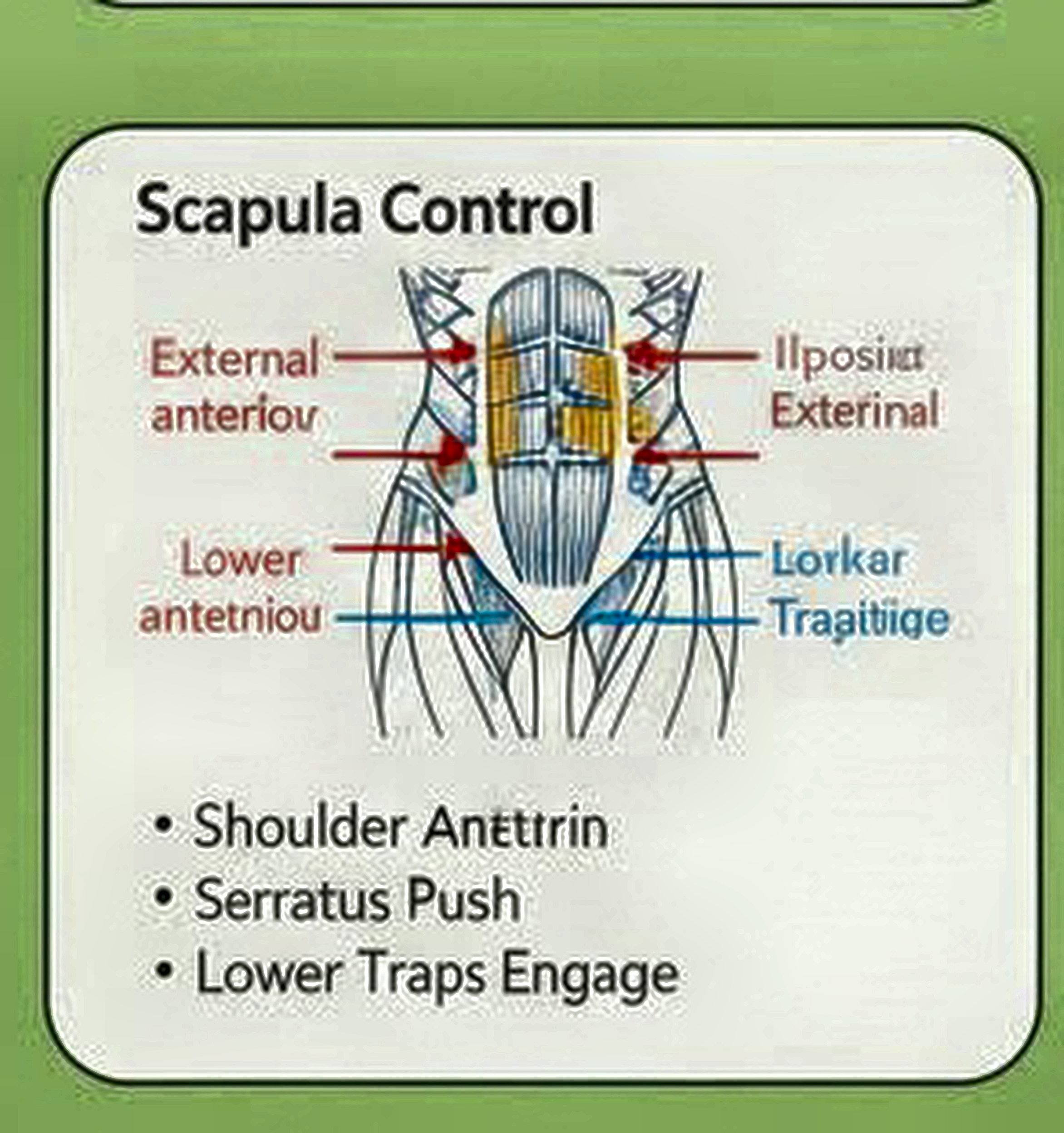
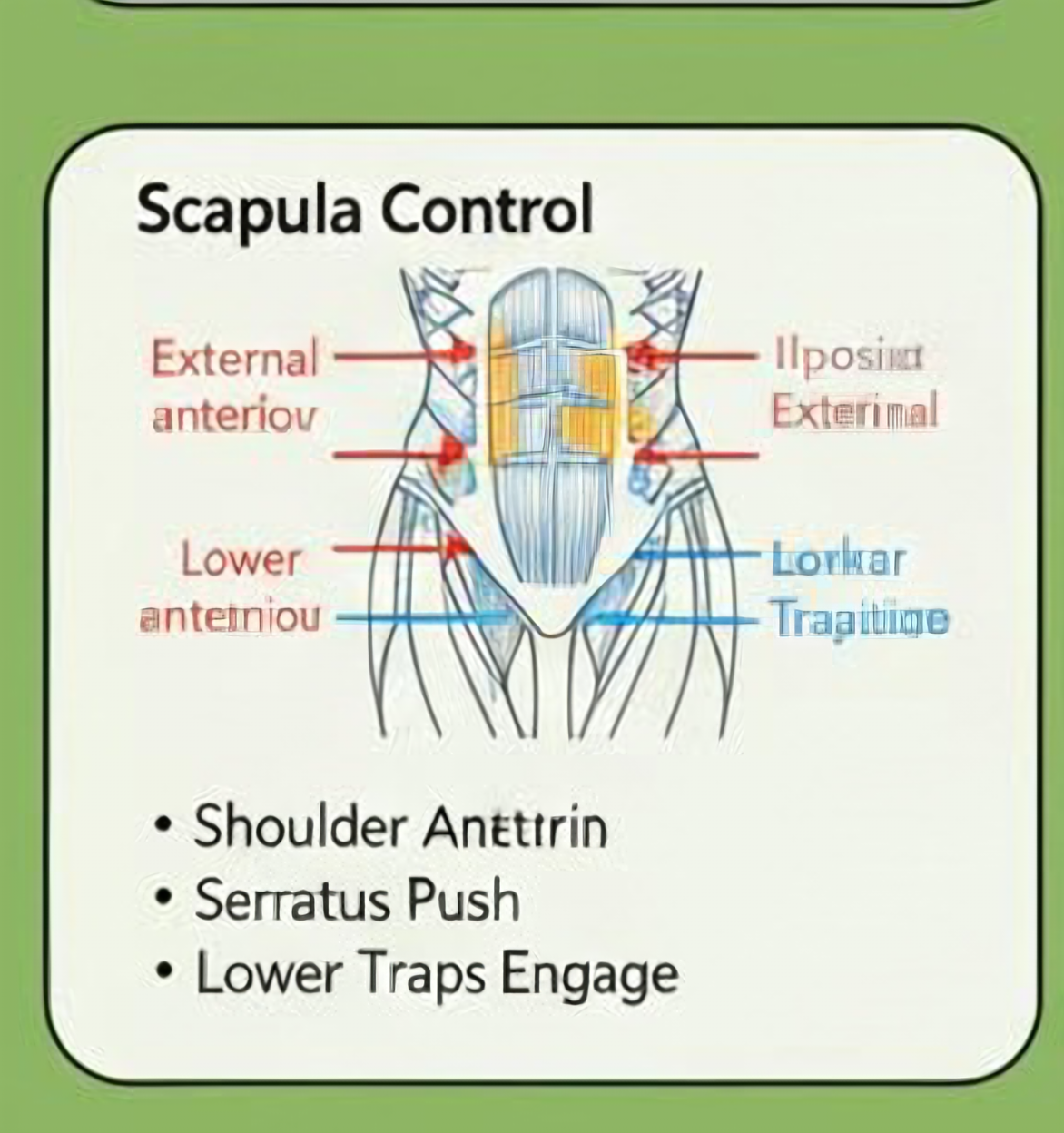
Bench
这是本机实测(pyenv Python 3.10 + OpenCV),不同机器会变,但相对量级很稳定:
EDSR 更吃内存,FSRCNN 极快。
CPU 情况:本次没有做精确 CPU% 采样;但 SR 推理是明显 CPU-bound 的短任务(EDSR 更重)。 若你要批量跑,优先 FSRCNN 或限制并发。
Constraints
Real-ESRGAN-ncnn-vulkan / waifu2x-ncnn-vulkan 在本机报 Vulkan/Metal 兼容问题(MoltenVK
VK_ERROR_INCOMPATIBLE_DRIVER),因此本次 AI 路线采用 OpenCV DNN(CPU 可跑)。
系统 Python 3.12 无 cv2;本次用 pyenv 的 Python 3.10 + OpenCV 来跑 SR。后续 skill
会做解释器自检与回退。
Repro
python3 scripts/image_enhance_compare.py --in tmp/scapula.png --scales 4,8 --html docs/image-upscale-compare会生成一份 data-URI 内嵌对比页(本地查看很方便,但不适合部署到 Vercel)。
node 8_Workflow/video/OLDLIFEASSONG/TOOLS/cartoon/upload-to-r2.js \\
--src tmp/r2-upload/image-upscale-scapula/20260123-175739 \\
--bucket pic \\
--prefix image-upscale/scapula-control/20260123-175739
需要预先配置 Cloudflare 账号/Token(脚本会读对应 .env);上传后会在同目录写入每个文件的
*.json(记录 public URL)。
Closing summary:当目标是“读清楚”,请优先重建信息(OCR/矢量/重排版);当目标是“看起来更清晰”,才把超分当主力。